The description for this assignment is as follows: “Given a non-normally distributed population such as the bimodal population which is pictured in figure 6-8, discuss and explain how such a population can have a frequency distribution of sample x-bars as shown in figure 6-9. How does Figure 6-8 relate to Figure 6-9 and then how does figure 6-9 relate to 6-10? Explain what concept is being demonstrated. In short write an explanation of how we move from figure 6-8 to 6-9 to 6-10.” This assignment was the second written response assignment for the Statistics II course (Quantitative Tools for Management) during the Spring 2007 semester at the University of Massachusetts at Amherst’s online program; I received a 5/5 for the below answer:
Looking at figure 6-8*,
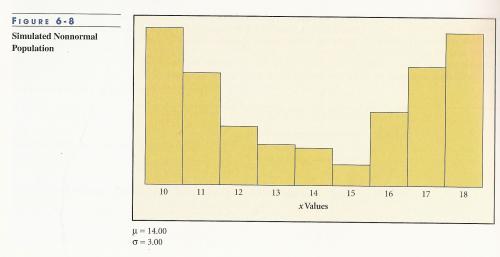
we see that the x values with the highest frequency are 10 and 18, the lower and upper limits of the x values, respectively. This population is not exactly symmetrical but is close to being so, as it closely resembles a “U” shape. Figure 6-9* shows the distribution of the average mean of 3 x values chosen at random, 3000 times.
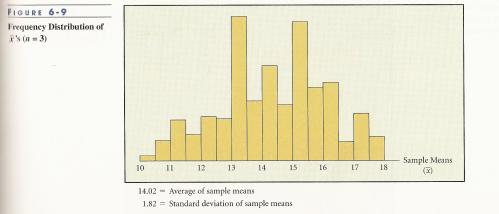
Even though 10 and 18 are the most common x values in the population, there are only a few average mean x values in the distribution in figure 6-9. In order to have a sample mean of 10 or 18 all three x values in a random sample would be to be all 10 or all 18. Thus the probability of choosing three 10’s or three 18’s in a random sample is quite low, thus why the distribution for 10 and 18 is so low in figure 6-9. Moving to the middle of figure 6-9, shows a rise in the number of occurrences of the sample means ranging from 13 to 16. Again, this makes sense because there are many more ways a sample mean could be in the 13 to 16 range and thus would be more commonly chosen in a random sample. Since an increasing amount of sample means will lie in the middle of the range, the standard deviation will be lower than the total population, as a higher proportion of the values will be closer to each other; whereas a high proportion of the values for the population in figure 6-8 lie at the upper and lower limits of the range, thus increasing the probability that the deviation between any two randomly chosen values will be higher.
Looking at figure 6-8, an eyeball estimate would lead me to say the median for this population would lie somewhere between 13 and 15. Figure 6-9 is showing that for 3,000 random samples of size 3, it is more likely the average mean will be close to the median than at the upper or lower limits [in this example, the median is equal to the mean of the total population, this is not always the case and when the median and mean are not equal the middle (and highest point for a high sample size) of the distribution in figures 6-9 and 6-10 will approach the mean].
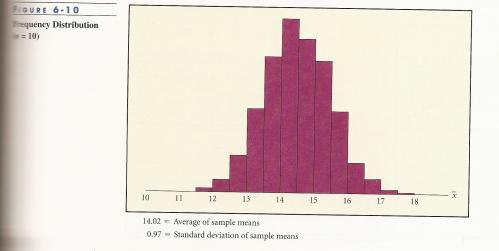
By increasing the sample size to 10, and thus increasing the reliability and accuracy of the results, figure 6-10* is showing that as more and more x values are included in the sample, the sample mean will approach the population mean because the chance of picking ten x values that average out to be similar to the population mean is higher than in a sample of three. Since the likelihood of ten random values equaling the population mean is higher in figure 6-10, the population mean is the value most often represented in the 3,000 random average means. Likewise, since the likelihood of the average mean of ten random values being equal to or close to the upper or lower limits is low, these values are either not represented or much less so than the population mean. The principle behind figure 6-10 is that if 3,000 random samples were taken, with a sample size close to or equal to the population size, the average means would all come out close to or equal to the population mean, the proximity of the sample size to the population size determines the range of the distributions we see in figures 6-9 and 6-10 and increases (if sample size is not close to population size) or decreases (if population size and sample size are close or equal) the deviation between values. If the sample size was close to or equal to the population size, the standard deviation would be close to or equal to zero (as most of the average means would be equal to the population mean).
The idea being shown through these three figures is the Central Limit Theorem, which in essence states that as a sample size increases, so does the resemblance of the sample distribution of the average means to a normal distribution (e.g. the shape shown in figure 6-10).
*All graphs are courtesy of Course in Business Statistics 4th Edition by David F. Groebner, Patrick W. Shannon, Phillip C. Fry, and Kent D. Smith